Radxa Fogwise AirBox is now available for pre-order!
The era of local generative AI has arrived — AirBox now open for pre-orders! Experience Llama3 online today!
Radxa Computer has launched the world's first SG2300X Mini AI Box, now available for pre-order on Arace.tech for just $321!
Major players vie for edge generative AI.
In 2024, running generative AI at the edge has become almost standard for the next generation of chips from companies like Intel, AMD, and Qualcomm.
The Rabbit R1, which gained traction at CES, promises natural language control of many smartphone apps using ChatGPT. While it sparked excitement among media, users who actually tested the product found single-task response times exceeding 20 seconds, leading to a poor user experience.
In situations where network access is poor, how can we achieve real-time, low-latency responses? The answer lies in placing generative AI services at the edge, rather than constantly transferring between the cloud, data centers, and edge nodes. Built on the SG2300x platform, the edge generative AI box Airbox boasts speeds of up to 12 tokens/s and StableDiffusion renders in just 1 second, bringing generative AI within reach.

Powered by SG2300X
| Specifications | SG2300X |
|---|---|
| Processor | Arm A53 8-core 2.3GHz |
| Memory | LPDDR4x 4.266 Gbps 128bit 68.256 GB/s; Max capacity supports 16GB |
| AI Performance | 24 TOPS INT8; 12 TFLOPS FP16/BF16; 2 TFLOPS FP32; Supports mixed precision computation |
| Video Decoding | H.264 & H.265: 32 channels 1080P @25fps; Max resolution supports 7680 * 4320 |
| Video Encoding | H.264 & H.265: 12 channels 1080P @25fps; Max resolution supports 7680 * 4320 |
| Image Decoding/Encoding | JPEG: Decode 750 frames/sec @1080P; Encode 250 frames/sec @1080P; Max resolution supports 32768 * 32768 |
| Video Post-processing | Supports image CSC (RGB/YUV/HSV), resize (1/128~128), crop; Supports padding, border, font, contrast, and brightness adjustment; Max resolution supports 8192 * 8192; Images with resolutions exceeding this can be processed and stitched after cutting |
| High-speed Interfaces | PCIe Gen3 X16 EP, configurable as X8 RC + X8 EP, supports cascading; 2 Ethernet RGMII interfaces, supports rates of 10/100/1000Mbps; 1 SD/SDIO controller; 1 eMMC 5.1, bus width 4-bit |
| Low-speed Interfaces | 1 SPI Flash interface; 3 UART interfaces, 3 I2C interfaces; 2 PWM interfaces, 2 fan speed detection interfaces; 32 general IO |
| Security | Supports AES/DES/SM4/SHA/RSA/ECC acceleration; Supports true random number generation; Supports secure key storage mechanism, secure boot, Trustzone |
| Typical Power Consumption | 20W |
| Operating Temperature | -40°C ~ +105°C |
| Toolchain | Supports TensorFlow/Pytorch/Paddle/Caffe/MxNet/DarkNet/ONNX; Supports TensorFlow/Pytorch/Paddle/TensorRT as well as customer-customized INT8, FP16, BF16 quantization algorithms |
The SG2300X processor, with its 24 TOPS of computational power, can smoothly run generative AI models like LLAMA-2 7B.

The remarkable computational power of SG2300X enables it to process more data in shorter time frames, resulting in faster response times and delivering users a smoother and more intelligent experience.

Radxa Fogwise AirBox

The Radxa Fogwise AirBox, developed by the Radxa team, is an edge AI box powered by SG2300X. It boasts a high computational power of up to 24 TOPS@INT8 and supports multiple precisions (INT8, FP16/BF16, FP32). It supports the deployment of mainstream AI models such as private GPT and text-to-image, and comes equipped with an aluminum alloy casing, allowing deployment in harsh environments.
| Specifications | Radxa Fogwise AirBox |
|---|---|
| Form Factor | 104mm x 84mm x 52mm |
| Processor | SOPHON SG2300X SoC, Eight-core Arm® Cortex®-A53 (Armv8) @ 2.3GHz |
| TPU | Tensor Processing Unit, Computational Capability: Up to 24TOPS (INT8), 12TFLOPS (FP16/BF16), and 2TFLOPS (FP32) |
| Supports leading deep learning frameworks including TensorFlow, Caffe, PyTorch, Paddle, ONNX, MXNet, Tengine, and DarkNet | |
| Memory | 16GB LPDDR4X |
| Storage | Industrial-grade 64GB eMMC |
| 16MB SPI Flash | |
| Offers SD card slot for high-speed SD card | |
| Multimedia | Supports decoding 32 channels of H.265/H.264 1080p@25fps video |
| Fully handles 32 channels of Full HD 1080P@25fps video, involving decoding and AI analysis | |
| Supports encoding 12 channels of H.265/H.264 1080p@25fps video | |
| JPEG: 1080P@600fps, supports up to 32768 x 32768 | |
| Supports video post-processing, including image CSC, resizing, cropping, padding, border, font, contrast, and brightness adjustment | |
| Connectivity | 2x Gigabit Ethernet ports (RJ45) |
| 1x M.2 M Key (2230/2242) for NVMe SSD | |
| 1x M.2 E Key for WI-FI/BT | |
| Operating Temperature | 0°C to 45°C |
| Casing | Corrosion-resistant aluminum alloy casing |
| Heat Dissipation | PWM-controlled fan with custom heatsink |
AirBox Run Local Generative AI
With high computational power and large memory, AirBox Run Local Generative AI Running the Llama-7B model on SG2300x, with weight quantization to INT4 and computation utilizing FP16, achieves up to 80% utilization during the first token calculation. Subsequent inferences benefit from kvcache, reducing computational demands while data transfer time completely covers computation time, shifting the bottleneck from computation to bandwidth.
Models like StableDiffusion continuously demand intensive computational power. Therefore, efficient execution of both LLM and Stable Diffusion models necessitates both high computational power and large memory. The main controller SG2300x in Airbox boasts 24TOPS of INT8, 12TFLOPS of FP16, 16G of memory, and 128-bit bandwidth, perfectly suited for the task.
Local execution with response times controlled within 1 second greatly enhances user experience. For instance, the latency of the qwen-7b model running on Airbox is 0.6s, with subsequent inference speeds reaching 12 tokens/s, meeting the real-time requirements of scenarios like natural language querying and voice interaction.
Airbox also functions as a complete Ubuntu Linux server, supporting CASAOS independently. As long as devices are connected, they can share its computational power. Antique PCs, tablets, smartphones, NAS, speakers, story machines, TVs, and other devices can all harness generative AI capabilities, turning "one device, multiple uses" into reality.
$321! Unbeatable value
How does the efficiency of running generative AI locally on AirBox compare to mainstream edge computing products?
Taking various models from the Nvidia Jetson series that support generative AI as an example, the Jetson AGX Orin 32GB version is priced at $1097 on Amazon.com, while the 64GB version costs $2137.
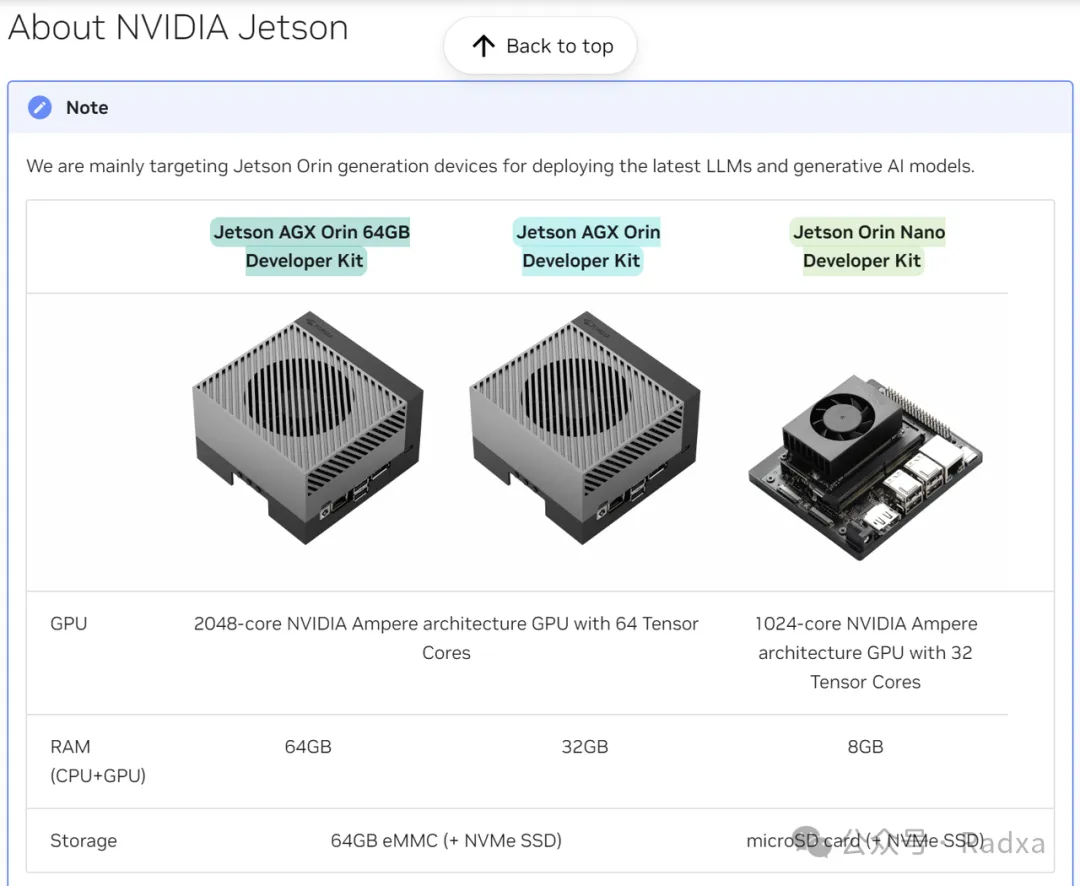
With MLC acceleration, AGX Orin achieves 47 tokens/s for Llama-7B and 25 tokens/s for Llama-2-13B. On Airbox, the performance for Llama2-7B is 12 tokens/s, while Llama2-13B achieves 6 tokens/s. Airbox supports int4, int8, and fp16 precisions, with similar performance for Llama2 and its various variants. A single core can handle models up to 20B-int4.

(Note: Data for Orin is sourced from the official NVIDIA website; higher values are better in this context.)
Based on testing, it's found that AirBox offers a significant advantage in terms of tokens per second per unit of currency (product price) compared to AGX Orin.
For Llama-7B:
- AGX Orin (64GB) ≈ 0.02199 tokens per second/USD
- AirBox ≈ 0.03738 per second/USD
For Llama-13B:
- AGX Orin (64GB) ≈ 0.01169 per second/USD
- AirBox ≈ 0.01869 per second/USD
On AGX Orin, Stable Diffusion takes 2.2 seconds per image, while SDXL takes 23.1 seconds. After utilizing LCM acceleration on Airbox, SD1.5 takes 1.1 seconds, and SDXL takes 7.4 seconds.

(Note: Data for Orin is sourced from the official NVIDIA website; Orin's step count is not specified, assuming 20 steps; lower values are better in this context.)
The rich ecosystem of applications
The Radxa Fogwise AirBox provides outstanding artificial intelligence performance, meeting your demands for powerful computing capabilities. This compact yet powerful device seamlessly integrates with leading deep learning frameworks like TensorFlow, PyTorch, and Caffe, offering users a portable and efficient AI experience. Whether you're a manufacturer, AI enthusiast, hobbyist, or professional, the Fogwise AirBox is your best choice.
Support for LLama 3
Support for LLama 3: Meta's latest open-source generative AI
Meta indicates that LLama 3 has demonstrated outstanding performance in multiple key benchmark tests, surpassing industry-leading models of the same kind. Whether it's code generation, complex reasoning, following instructions, or visualizing ideas, LLama 3 has achieved comprehensive leadership. The model excels in the following five benchmark tests:
- MMLU (Subject Knowledge Understanding)
- GPQA (General Problem Question Answering)
- HumanEval (Code Ability)
- GSM-8K (Mathematical Ability)
- MATH (High-difficulty Mathematical Problems)
Faced with the exciting performance of LLama 3, the Airbox team responded actively, quickly porting LLama 3 8B and successfully running it on Airbox. The video showcases LLama 3 8B running on Airbox.
(Note: LLama 3 8B's knowledge is updated until March 2023)
As you can see, LLama 3 8B runs extremely smoothly on Airbox, achieving a processing speed of 9.6 tokens/s, fully demonstrating its practical value.
The AirBox team has taken the lead in launching an online experience based on LLama 3 8B on AirBox. We welcome everyone to personally experience the outstanding performance of LLama 3 and the powerful computing power provided by AirBox.
(Note: The service is based on a single AirBox deployment. If there is a high volume of concurrent users, there may be queues. For a deeper experience, we recommend trying during off-peak hours.)
Support CASA OS
A lightweight and feature-rich open-source dashboard system
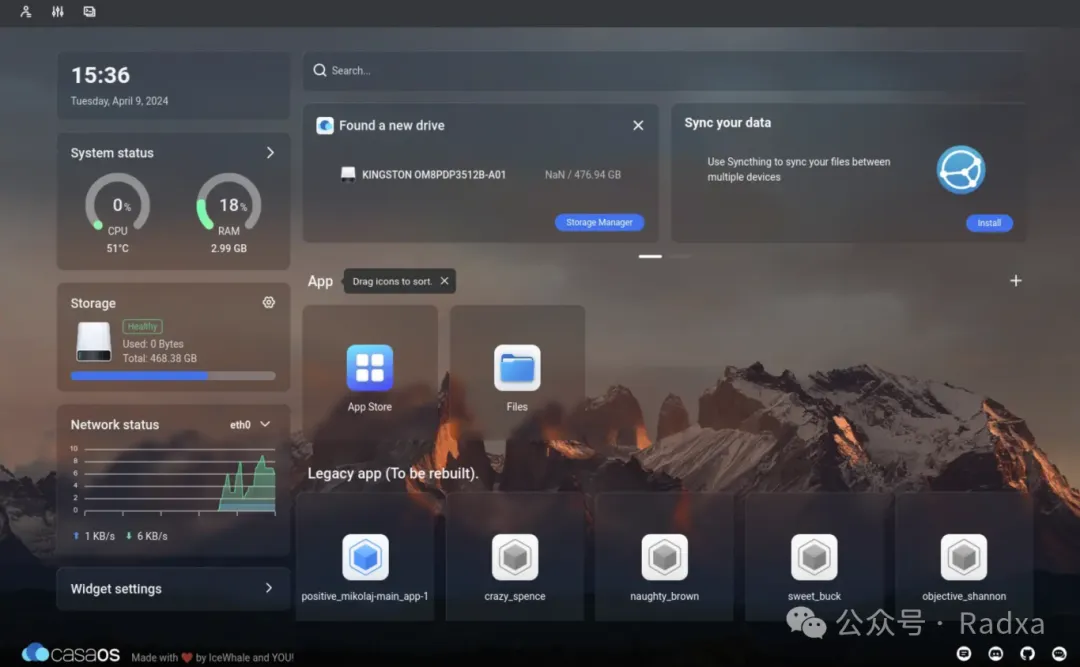
Install generative AI apps with just one click
Currently supported popular models include Stable Diffusion, Whisper, ImageSearch, ChatDoc, and more. Install them with just one click, eliminating the need for tedious environment configuration.

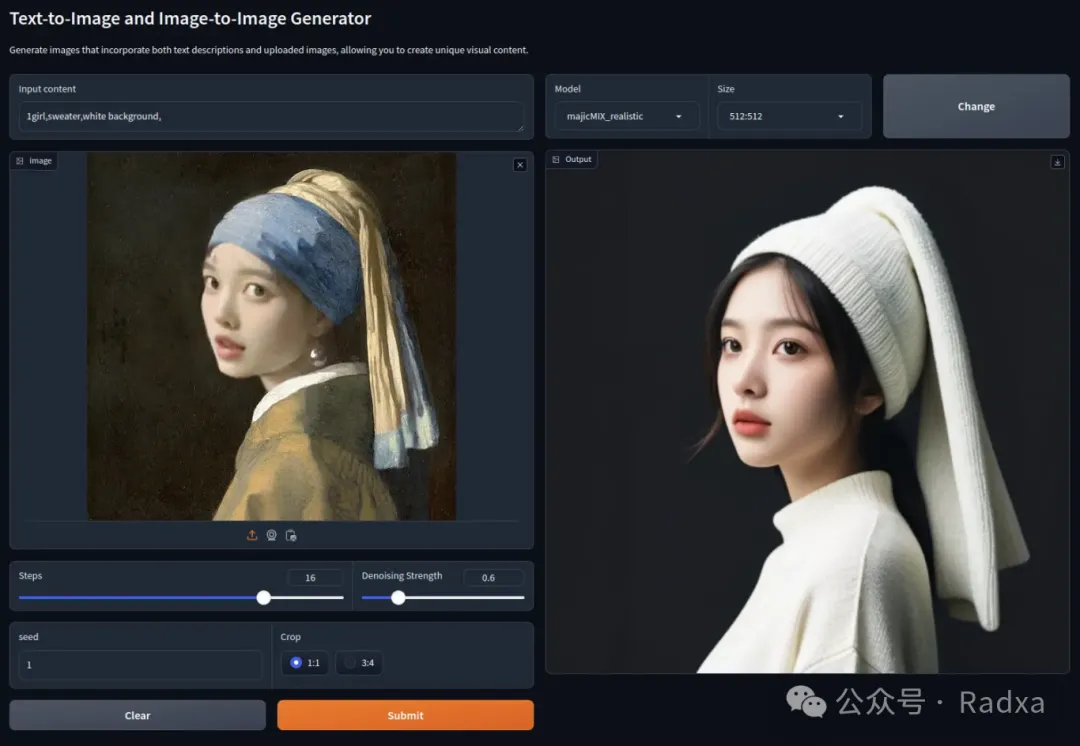
Text to Image, Image to Image
The AirBox team has conducted deep optimizations and adaptations for StableDiffusion, enabling lightning-fast image generation. We support online model replacement for added flexibility.
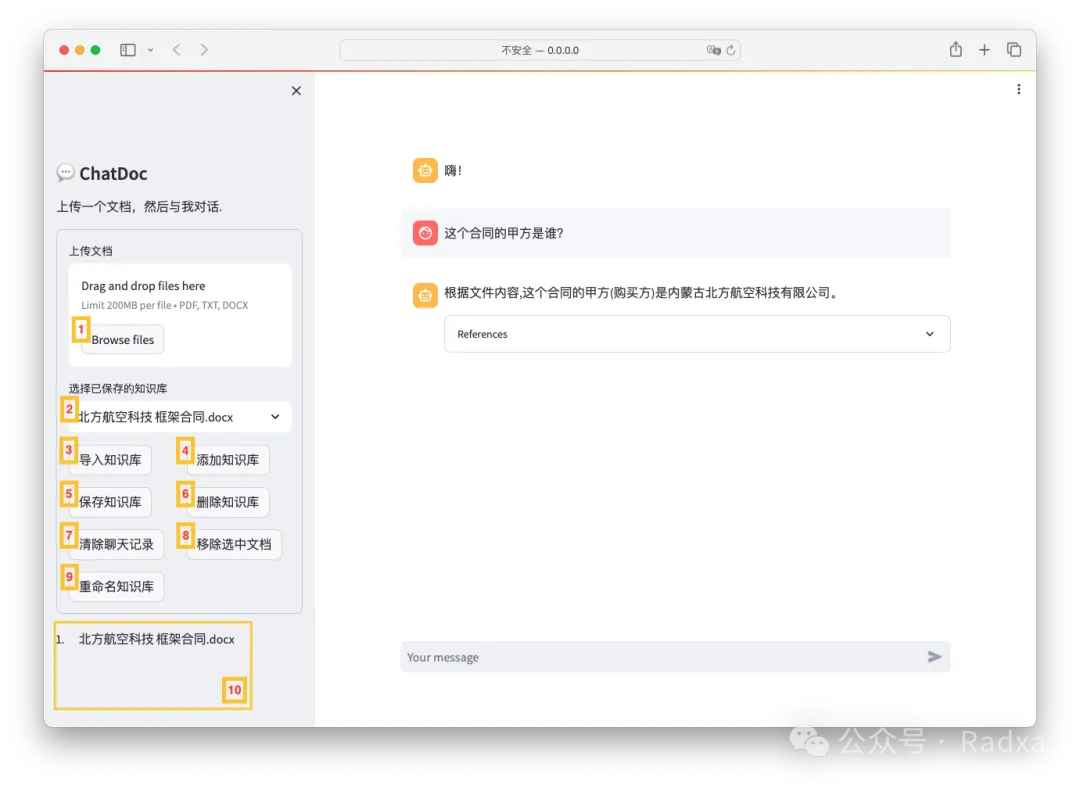
Support ChatDoc
ChatDoc: Let AI Understand Your Documents
Empower AirBox to be your personal data steward.
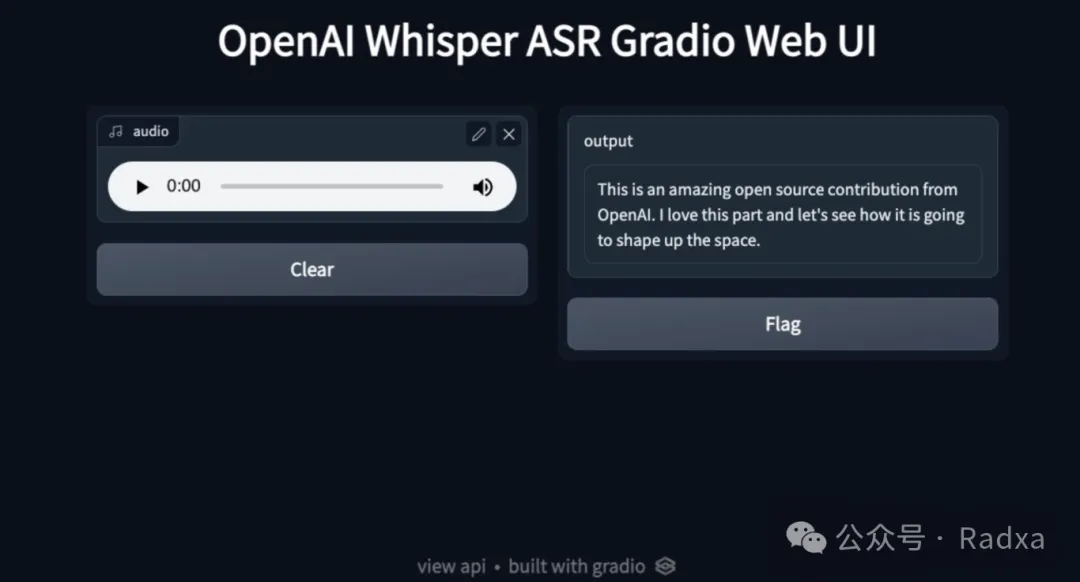
Support Whisper
Whisper: Real-Time Text Transcription in Over a Hundred Languages Whisper, an efficient speech recognition model, seamlessly converts speech into text in real-time, supporting nearly a hundred languages. This greatly enhances the convenience and accuracy of information retrieval. Whether it's recording meetings, real-time multilingual translation, or providing live captions for the hearing-impaired, Whisper offers robust support. Multiple sectors including education, healthcare, and law stand to benefit from its precise and rapid speech transcription services.
In the future, leveraging generative AI models like LLaMa, Stable Diffusion, Whisper, and others will give rise to a plethora of cross-modal applications, ushering in unprecedented AI capabilities spanning across speech, image, and text domains. Imagine this scenario: an all-encompassing personal assistant AI equipped with Whisper and TTS models for authentic multilingual capabilities, providing real-time translation and transcription for conversations in any language worldwide. Additionally, leveraging Stable Diffusion to create visual content to aid communication, this would revolutionize the way international conferences, remote education, and global collaborations are conducted, accelerating the advent of the digital world!
AirBox Model Zoo
One-click Deployment of Popular Models
Comes with a rich collection of AI application examples, ready to use out of the box.
For more details, please visit
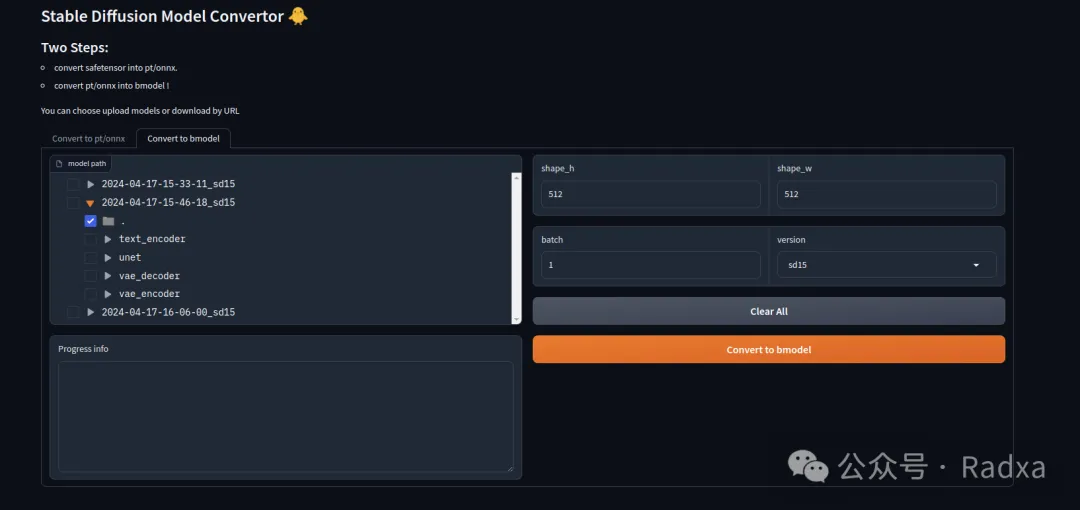
Graphical Model Conversion Tool
Easily Deploy Models to AirBox via Graphical Interface
To ensure a seamless user experience, AirBox has developed a feature for one-click conversion of Civitai and Huggingface models. With just a few clicks on the GUI interface, deploying the Stable Diffusion model on AirBox is now effortless.

With the model conversion tool, you can effortlessly deploy open-source generative AI models from HuggingFace and Civitai to AirBox, embracing the latest AI technologies.
AICore SG2300X
Empowering Enterprises to Easily Attain High-Performance AI Product Capabilities
The Radxa AICore SG2300X is a computing module equipped with the advanced SOPHON AI processor SG2300X, delivering powerful performance to unleash your full potential. With 16GB of memory and 64GB of eMMC storage, the Radxa AICore SG2300X boasts an impressive 24 TOPS INT8 computational capability, excelling in various tasks and fully supporting mainstream deep learning frameworks. Integrated with core circuits and components, it significantly accelerates product development speed, making it the preferred choice for enterprises to rapidly develop high-performance AI products.
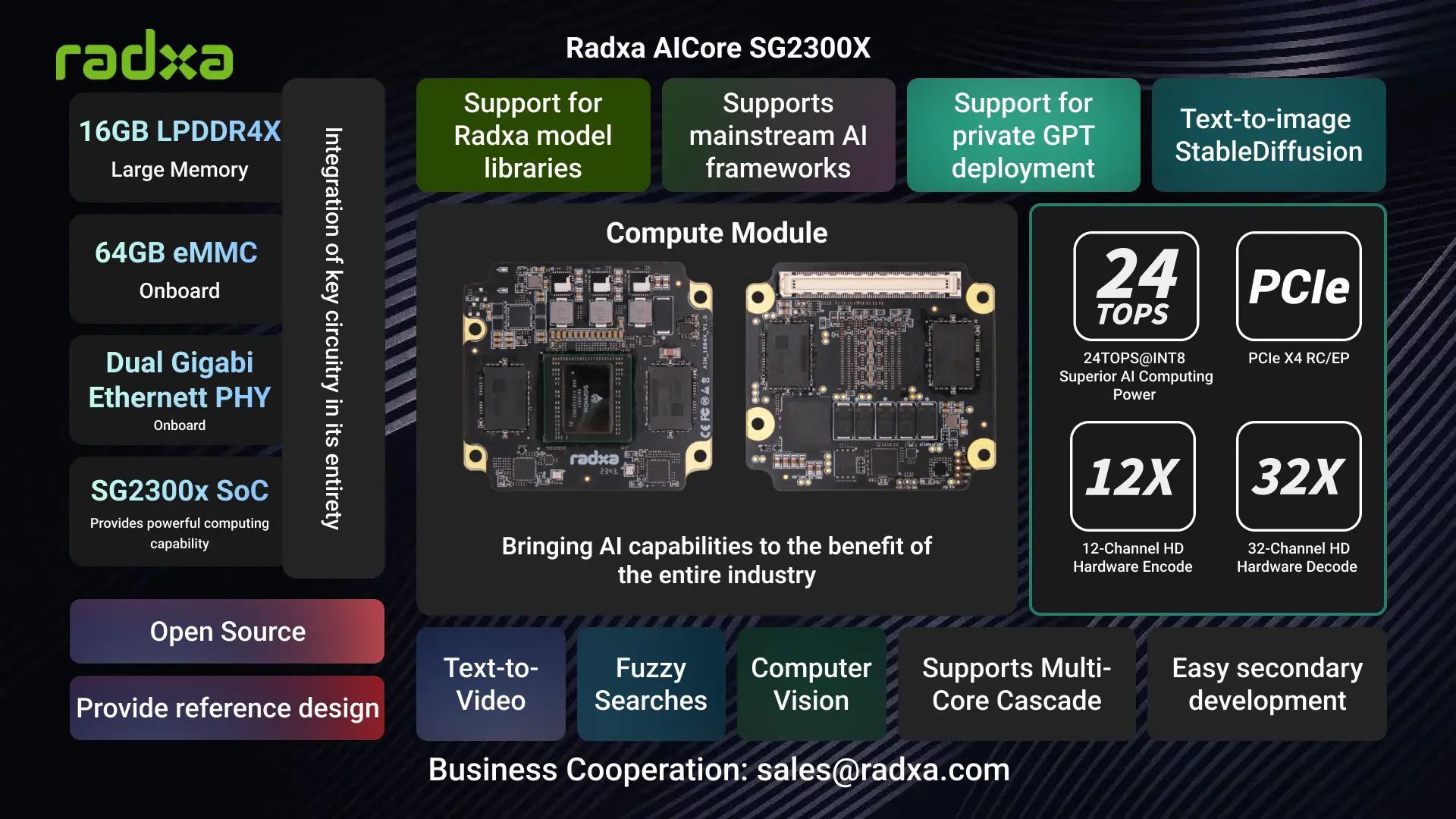
Radxa provides ODM/OEM services for industry partners, leveraging the rich engineering experience on the SG2300X platform to maximize the acceleration of productization in various industries.
Radxa Fogwise AirBox now available for Pre-order
You can now pre-order the AirBox at arace.tech.
Pre-order before May 20 and get gift for free
- 20V/3A Power adapter
- USB MIC
- Intel WIFI6 Wireless Module